第67回ブログ|Alembic入門から実運用まで ― PythonのDBマイグレーションを事故なく回すために
PythonでWebアプリや業務システムを開発していると、避けて通れないのがデータベースのスキーマ変更です。テーブルを追加する、カラムを増やす、制約を見直す、既存DBに版管理を導入する。こうした変更を手作業でSQL管理していると、環境差分や適用漏れ、ロールバック不能といった事故が起きやすくなります。
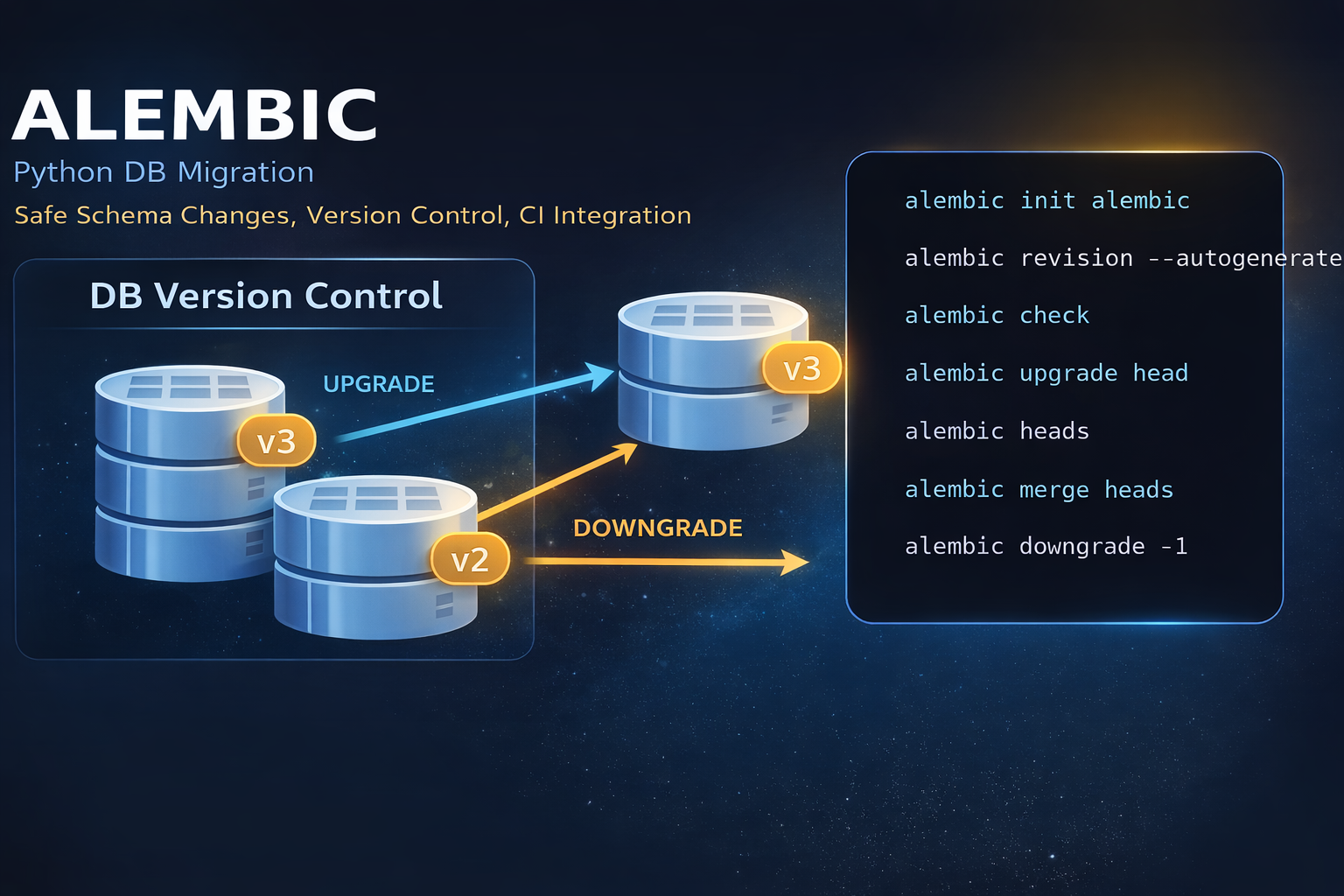
そこで重要になるのが Alembic です。Alembicは、SQLAlchemy系プロジェクトで広く使われているDBマイグレーションツールで、スキーマ変更を revision として履歴管理し、upgrade と downgrade で順序立てて適用できます。
今回は、単なる「使い方メモ」ではなく、初心者が最初につまずきやすい点から、CI・複数人開発・データ移行・multiple heads対策まで、実運用に耐える視点でまとめます。
- Alembicとは何か、何をしてくれるのか
alembic.iniとenv.pyが重要な理由--autogenerateをどこまで信用してよいのか- CIで最低限入れたい検査
- multiple heads、stamp、データ移行の考え方
- チーム開発で事故を減らす運用ルール
1. Alembicとは何か
Alembicは、SQLAlchemyを基盤にした軽量なマイグレーションツールです。アプリケーション側のモデル定義と、実際のDBスキーマとの差分を見ながら、変更履歴をスクリプトとして積み上げていけます。
ポイントは、単に「今の状態を合わせる」だけではなく、どの順番で何を変えてきたかを履歴として持てることです。これにより、開発環境・検証環境・本番環境で同じ変更を同じ順番で適用しやすくなります。
Pythonアプリの成長に合わせてDB構造が変わるなら、早めに導入しておいたほうが圧倒的に安全です。
2. 最初に覚えたい全体像
Alembicを初期化すると、典型的には次のような構成になります。
| 要素 | 役割 | 実運用での見どころ |
|---|---|---|
alembic.ini |
メイン設定ファイル | script_location、DB接続、revisionファイル命名、hook設定などを持つ |
env.py |
マイグレーション実行コンテキスト | 接続、トランザクション、比較条件、target_metadata設定の中核 |
versions/ |
revisionスクリプト群 | 変更履歴そのもの。チーム開発では競合とhead管理が重要 |
script.py.mako |
revision雛形テンプレート | 社内ルールに合わせたヘッダやコメントを強制しやすい |
つまり、Alembicの本質は「コマンド」だけではありません。alembic.ini と env.py をどう設計するかで、あとからの運用のしやすさが大きく変わります。
3. まず動かすための最短コース
最初の流れはシンプルです。
alembic init alembicで環境を作るalembic.iniとenv.pyを調整する- アプリの
Base.metadataをtarget_metadataに渡す alembic revision --autogenerate -m "..."で候補を作る- 生成されたrevisionをレビューして修正する
alembic upgrade headで適用する
生成された差分は必ずレビューしてください。これを省くと、後で確実に痛い目に遭います。
4. よく使うコマンドを用途別に整理する
| コマンド | 主用途 | 注意点 |
|---|---|---|
alembic init <dir> |
環境作成 | テンプレート選択を誤ると後で辛い |
alembic revision -m "msg" |
空のrevision作成 | 手書きで安全に作りたい変更に向く |
alembic revision --autogenerate -m "msg" |
差分候補の生成 | 必ずレビュー・手修正が必要 |
alembic upgrade head |
最新revisionまで適用 | multiple heads状態では曖昧になり失敗しやすい |
alembic downgrade -1 |
1つ前に戻す | データ移行が絡むと元通りにできない場合がある |
alembic current |
現在のrevision確認 | 本番障害時の現状確認で重要 |
alembic heads |
head確認 | 複数headの早期発見に必須 |
alembic merge heads |
分岐統合 | merge revisionは統合用として必要最小限に保つ |
alembic stamp head |
version tableだけ合わせる | 実スキーマが本当に一致しているときだけ使う |
alembic check |
CI向け差分検査 | migration追加忘れを自動検知できる |
5. alembic.ini と env.py は、なぜそんなに重要なのか
初心者のうちは、どうしても revision や upgrade のコマンドに目が行きます。しかし、実際に運用を左右するのは alembic.ini と env.py です。
5-1. alembic.ini で見るべき点
script_location:マイグレーション環境の場所sqlalchemy.url:DB接続情報file_template:revisionファイルの命名規則version_locations:複数lineage運用時に重要post_write_hooks:blackやruffなどの自動整形
特に実運用では、DB接続URLを直書きし続けないことが大切です。環境変数やデプロイ時注入に寄せておくほうが安全です。
5-2. env.py で決まること
env.py は、Alembicコマンドが動くたびに実行されるスクリプトです。ここで接続、トランザクション、比較対象、offline/onlineの挙動などを決めます。
とくに重要なのは、context.configure(...) に何を渡すかです。ここで、型比較、default比較、比較対象スキーマ、バッチモードなどを制御します。
そして autogenerateを使うなら、アプリの target_metadata を正しく渡すこと が前提になります。
「なぜこの差分が出たのか」を説明できないまま使い続けるのは危険です。
6. autogenerateは便利だが、万能ではない
Alembic運用で最も誤解されやすいのがここです。--autogenerate は非常に便利ですが、完璧ではありません。むしろ、限界を理解して使うこと が前提です。
| 分類 | 代表例 | 実務での意味 |
|---|---|---|
| 比較的検出しやすい | テーブル追加、カラム追加削除、nullable変更、基本的なFK/Index | 日常的な小変更はある程度任せられる |
| 設定次第で検出 | 型変更、server default変更 | 比較精度やノイズに注意が必要 |
| 苦手・手修正前提 | テーブル名変更、カラム名変更、匿名制約、DB依存の差分 | そのまま適用すると意図しないadd/dropになる危険がある |
とくに危険なのが、リネームが add/drop として出ることです。これをそのまま適用すると、構造だけでなくデータまで壊しかねません。
「そのまま流す」のではなく「意図通りかを読む」ところまでがセットです。
7. 命名規約を最初に入れておくべき理由
制約名やインデックス名をDB任せにすると、DB製品ごとの差や自動命名の揺れによって、autogenerateのノイズや、downgrade時の失敗が発生しやすくなります。
よくあるのが、drop_constraint(None, ...) のように、制約名が分からない状態のままスクリプトが生成されてしまうケースです。これでは安全に戻せません。
そのため、SQLAlchemyの naming_convention を早い段階で整備することが重要です。これは小さな設定に見えて、運用コストを大きく左右します。
8. CIで最低限やっておきたいこと
チームで開発するなら、revisionの作り忘れを人間の記憶に頼ってはいけません。最低限、CIで次の2点を自動化したいところです。
alembic checkで未反映モデル差分を検知する- 検証DBで
alembic upgrade headを実行して通ることを確認する
さらに余裕があれば、ポリシーに応じて alembic downgrade -1 まで確認しておくと、スクリプトの破綻に早く気づけます。
「モデルを変更したのにmigrationを追加し忘れた」
という地味ですが非常に多いミスを防ぐのに効きます。
9. multiple heads問題をどう考えるか
複数人で並行開発していると、同じ親revisionから別々にrevisionが作られ、あとで multiple heads 状態になることがあります。
この状態で alembic upgrade head を実行すると、どのheadを指すのか曖昧になり、失敗の原因になります。
対処の基本は次の流れです。
alembic heads --verboseで現状確認alembic branches --verboseで分岐状況を確認alembic merge -m "merge heads" headsで統合
運用上は、「headは常に1つ」を原則にするだけでも事故率はかなり下がります。長命ブランチや複数モジュール構成でない限り、main系でmultiple headsを放置しないほうが安全です。
10. rollbackは万能薬ではない
初心者のうちは、downgrade があるなら何でも元に戻せるように思いがちです。しかし実際には、データ移行が絡むと完全に戻すのは難しい 場面が多くあります。
たとえば列の意味を変えた、データを別形式に変換した、大量バックフィルをした、といった変更は、構造だけ戻してもデータまで元通りにならないことがあります。
そのため実運用では、次のどれかを明確にしておく必要があります。
- 構造だけ戻せればよいと割り切る
- データ復元はバックアップや再計算で行う
- expand / contract の段階移行を採用する
- データ移行はAlembic外の別スクリプトに分ける
小規模な投入はともかく、重いUPDATEやバックフィルは設計を分けたほうが安全です。
11. 既存DBにあとからAlembicを入れるときの考え方
すでに動いているDBにAlembicを導入すると、最初のautogenerateで「全部差分」に見えてしまうことがあります。これは珍しいことではありません。
こういうときに使われるのが stamp です。alembic stamp head は、migrationを実行せず、version tableだけを現在状態に合わせます。
ただし、これは実スキーマが本当に対象revisionと一致していることが前提です。ずれている状態で安易にstampすると、あとから整合性が崩れて苦しくなります。
12. offline modeが役立つ場面
組織によっては、アプリケーション側が本番DBへ直接DDLを流せない場合があります。その場合は、alembic upgrade ... --sql でSQLスクリプトを生成し、DBA承認フローに乗せる運用が有効です。
この方式は堅実ですが、offlineではDB接続がないため、DB問い合わせ前提の処理は使えません。つまり、offlineでも成立するmigrationの書き方 を意識する必要があります。
13. SQLiteや特殊環境ではバッチモードも重要
SQLiteはALTER系の制約が強いため、Alembicではバッチモードが重要になることがあります。内部的には、単純なALTERではなく、テーブル作り直しに近い処理になることがあります。
このときも命名規約が効いてきます。特に、名前のない制約があるとdrop系操作が扱いにくくなります。
14. 実運用で起きやすいトラブルと見直しポイント
| 症状 | ありがちな原因 | 見直しポイント |
|---|---|---|
| upgrade headが失敗する | multiple heads | heads / branches 確認、必要ならmerge |
| FK差分が毎回出る | schema指定の揺れ、命名不統一 | include_schemas、モデル定義、命名規約を見直す |
| downgradeが失敗する | 制約名が不定、None扱い | naming convention導入を優先する |
| 初回migrationが全部差分になる | 既存DBと版管理未整合 | ベースライン確認後にstampを検討する |
| 本番反映時にロックが長い | 重いデータ移行を一括で実行 | 段階移行や別スクリプト化を検討する |
15. チームで回すなら、ここまでをルール化したい
個人開発では何とかなることも、チームになると急に事故率が上がります。そこで、次のようなルールを先に決めておくと安定します。
- headは原則1つを維持する
- autogenerate結果は必ず人が読む
- 制約名・Index名は命名規約で固定する
- データ移行は原則別設計にする
- migrationはアプリ起動と分離して単発ジョブ化する
- CIに
alembic checkとupgrade headを入れる
ルールが曖昧なまま人数だけ増やすと、DB変更は一気に危険になります。
16. 初心者に向けた結論
初めてAlembicに触れる方は、まず次の順で理解すると整理しやすいです。
- AlembicはDB変更の履歴管理ツールである
alembic.iniとenv.pyが運用の土台になる--autogenerateは便利だが、レビュー必須である- 命名規約とCIを早めに入れると後が楽になる
- rollbackやデータ移行は単純ではない
これを理解しておくだけで、Alembicは「怖いもの」ではなく、Python開発を堅実に進めるための強い味方になります。
17. ビットオンからのひとこと
Python、FastAPI、SQLAlchemy系の案件では、アプリケーションコードだけでなく、DBマイグレーション運用の設計まで含めて品質が決まります。開発初期は軽く見られがちな領域ですが、あとから効いてくるのはむしろこちらです。
ビットオンでは、単にアプリを実装するだけでなく、長く運用できるDB変更フロー、CIに組み込めるマイグレーション設計、既存システムからの安全な移行まで含めて整理しながら進めています。
「Alembicを入れたいが、今のDBにどう載せればよいか分からない」「autogenerateの差分が毎回おかしい」「本番リリースで安全に回る形にしたい」といった場合は、実装と運用の両面から一緒に整理できます。