第70回ブログ|Claude Code で進める「3段階開発フレームワーク」── Spike・Walking Skeleton・Milestone を国際標準設計手法とどう接続するか
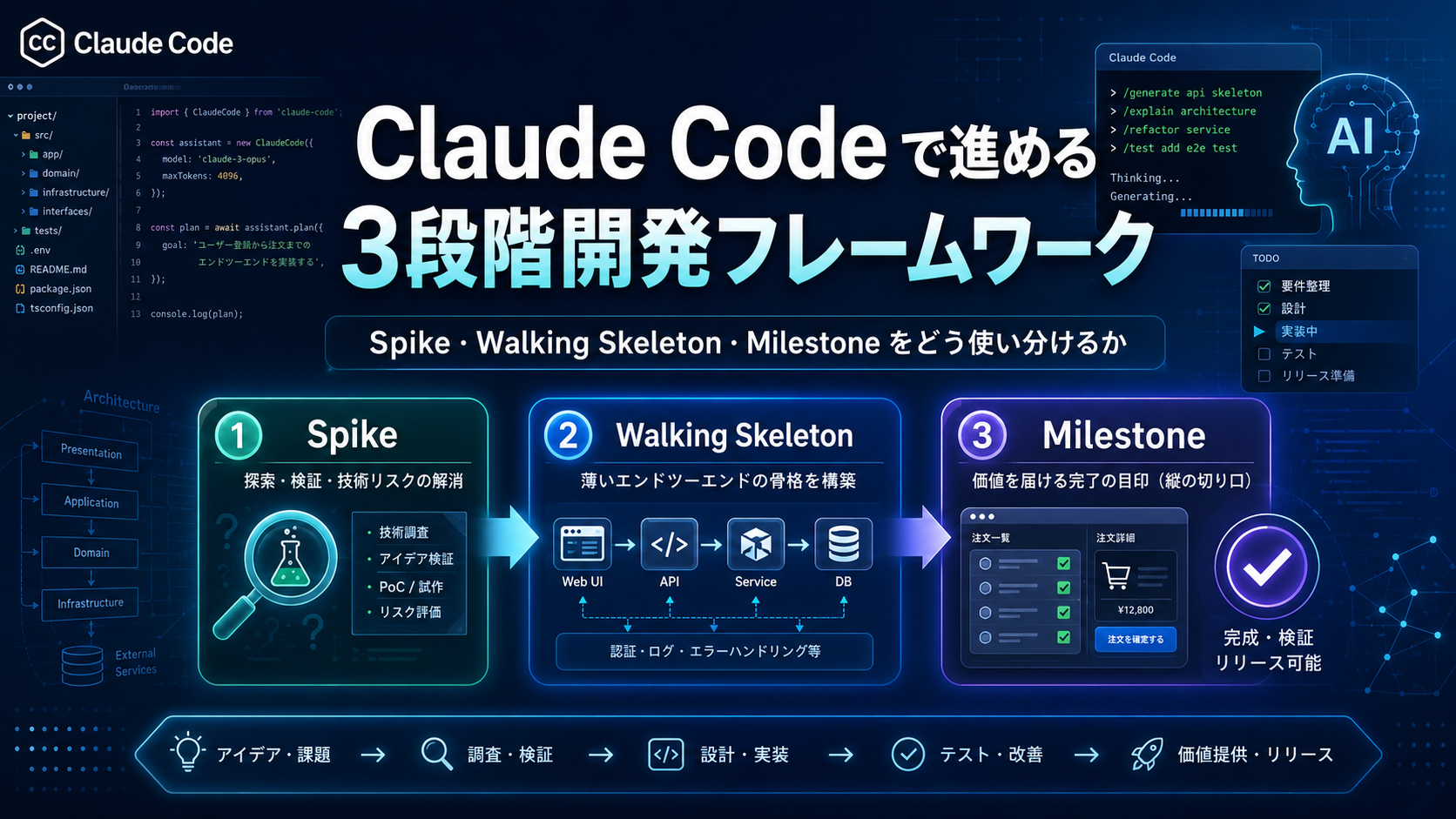
BitOnでは、Claude Code を用いた開発を Spike → Walking Skeleton → Milestone の3段階で進めている。 これは単なる社内ローカルルールではなく、Extreme Programming・Alistair Cockburn のアジャイル設計論・PMBOK / ISO/IEC/IEEE 12207 といった既存の国際標準的な設計手法を、AI支援開発時代に再構成したものだ。
この記事では、3段階それぞれの「目的」「Definition of Done」「Claude Code 上での具体的な構成内容(ディレクトリ・CLAUDE.md・サブエージェント・hooks・MCP)」を、実際に進めているプロジェクト kotonomi(失語症患者向け発話リハビリアプリ)を例にしながら、設計手法レベルで詳述する。「@katsujin」
1. なぜ「3段階」が必要なのか
Claude Code は、自然言語で意図を伝えるだけで、整った構造のコードを大量に生成できる。便利な反面、AI支援開発には構造的なリスクがある。
- 「もっともらしいが間違っているコード」を、検証コストより速く生成してしまう
- 不確実性を「探索」と「実装」のどちらで吸収すべきかの判断が曖昧になりやすい
- 設計の前提(アーキテクチャ制約・禁則事項)が文書化されていないと、セッションごとに揺れる
つまり、AI支援開発で起きる失敗のほとんどは「コードを書く力」ではなく「何を、どの順序で、どの解像度で書くべきか」という設計プロセス側の問題だ。 ここを支えるのが、ソフトウェア工学が長年蓄積してきた古典的な3つの概念 ── Spike・Walking Skeleton・Milestone である。
これらは三者三様の目的を持ち、混同してはいけない。
| 段階 | 主目的 | 出力物 | 捨ててよいか |
|---|---|---|---|
| Spike | 不確実性の偵察(知識獲得) | 知見ドキュメント | 基本捨てる |
| Walking Skeleton | エンド・トゥ・エンドの最小骨格 | 動くがほぼ空っぽのシステム | 捨てない(育てる) |
| Milestone | 検証可能な垂直スライス | 価値を届ける機能増分 | 捨てない(積み上げる) |
「捨てる前提のコード」と「育てるコード」を Claude Code に書き分けさせるには、それぞれを別の構成で運用する必要がある。
2. 3段階の起源と国際標準的位置づけ
それぞれの概念がどこから来て、どの標準と結びついているかを整理しておく。
2.1 Spike(XP, Ward Cunningham)
Extreme Programming で Ward Cunningham が提唱した概念。「不確実性の高い領域に 薄く深く一本の杭(spike)を打ち込み、リスクを定量化する」ためのタイムボックス化された探索。 本質は コードではなく知識を生産すること。実装は捨てる前提で、得られた洞察(性能の上限、ライブラリの制約、データ品質)だけを残す。
関連標準・概念:
- ISO/IEC/IEEE 12207 の "Risk Management Process"(リスク識別と低減)
- ADR (Architecture Decision Records)(Michael Nygard)に近い意思決定の記録形式
- リーンスタートアップの Build-Measure-Learn の "Measure" に相当
2.2 Walking Skeleton(Alistair Cockburn)
Alistair Cockburn が Crystal Clear および Agile Software Development で定式化した概念。 「最小機能で、しかし本物のアーキテクチャを端から端まで貫通したシステム」を最初に作る。
"A Walking Skeleton is a tiny implementation of the system that performs a small end-to-end function. It need not use the final architecture, but it should link together the main architectural components."
UIから永続化層まで、すべての層に一本の細い動脈を通す。Day 1 からCIが緑で、デプロイ可能であることが要件。
関連標準・概念:
- ISO/IEC/IEEE 42010(アーキテクチャ記述)── 主要コンポーネントの結線を最初に証明する
- C4 Model(Simon Brown)── Container 図のレベルが「歩ける」ことに等しい
- DevOps の "Deployment Pipeline First" 原則(Humble & Farley Continuous Delivery)
2.3 Milestone(PMI / PMBOK, IEEE 12207)
PMBOK で定義される、検証可能なプロジェクト到達点。期日ではなく、Definition of Done を満たした成果物で定義される。Scrum の Sprint Goal、SAFe の PI Objectives と同義に扱える。
関連標準・概念:
- PMI PMBOK 7th Edition の "Milestone" 概念
- ISO/IEC/IEEE 12207 の Stage Reviews
- Scrum Guide の Definition of Done(DoD)
- IEEE 1016(Software Design Descriptions)── 各 Milestone の設計を残す
2.4 3者の関係:不確実性吸収のレイヤー
3つは「直列に並んだ別の作業」ではなく、不確実性を異なる粒度で吸収する三層だと理解するのが正確だ。
不確実性高 ─────────────────────────────────────► 不確実性低
│ │ │
▼ ▼ ▼
Spike Walking Skeleton Milestone
(知識の獲得) (構造の証明) (価値の積み上げ)
Spike が先行する Walking Skeleton も、Milestone のなかで小さく行う Spike も、両方ありうる。重要なのは その瞬間に何を確かめているのか を言語化しておくことだ。Claude Code の各段階の構成は、ここに合わせて変える。
3. Claude Code の構成要素 ── 設計手法から見たマッピング
3段階の運用に入る前に、Claude Code 側の道具立てを設計プロセス的に分類しておく。
| 構成要素 | 配置 | 設計的役割 | アナロジー |
|---|---|---|---|
CLAUDE.md |
プロジェクト直下 | 常に真の前提・制約・規約 | 建築の「設計指針書」 |
| Slash Commands | .claude/commands/*.md |
再現可能な手続きの起点 | Makefile ターゲット |
| Skills | .claude/skills/<name>/SKILL.md |
必要時に読み込まれる手順書 | プレイブック |
| Subagents | .claude/agents/*.md |
隔離されたコンテキストの専門家 | マイクロサービス |
| Hooks | settings.json / agent frontmatter |
決定論的ライフサイクル制御 | リーン生産方式の poka-yoke |
| MCP servers | settings.json |
外部ツール・データへの接続 | エンタープライズ統合パターン |
ここで強調したいのは、CLAUDE.md と Hooks は性質が全く違うということだ。CLAUDE.md は「モデルがその内容を理解し従う」前提で動くソフトな規範。Hooks は「モデルがどう解釈しようと、シェルスクリプトが実行されて結果がブロック/通過する」決定論的な統制。前者は規則、後者は反射神経に相当する。
設計プロセスでは、重要な制約ほど Hooks に落とし、揺らがせたくないものは決定論で守る。
4. Stage 1: Spike ── 不確実性の偵察
目的
技術リスクを最小コストで定量化し、後続の設計判断の根拠を作る。
Definition of Done
- 当初の問い(Risk Question)に対する Yes / No / 条件付き Yes の判定が出ている
- 判定の根拠となる計測値・再現手順が残っている
- 本体リポジトリの本流にコードがマージされていない(これが最大のDoD)
Claude Code 構成
Spike はリポジトリの本流から 物理的に隔離する。これは XP 由来の「捨てる前提」を構造で担保するためだ。
project-root/
├── CLAUDE.md # 本体用(Spikeとは無関係)
├── src/ # 本体
└── spikes/
└── 2026-05-whisper-lora-dysarthria/
├── CLAUDE.md # Spike専用・軽量
├── RISK_QUESTION.md # 何を確かめるか
├── notebook/
├── data_sample/
└── FINDINGS.md # 知見(成果物)
Spike用 CLAUDE.md(軽量版)
# Spike: Whisper LoRA fine-tuning for dysarthric speech
## Risk Question
構音障害のある音声 100 サンプルに対し、Whisper large-v3 + LoRA で
- 単語単位 WER を 0.4 以下に下げられるか
- RTX 5060 Ti 16GB VRAM で実用時間内に学習が回るか
## Constraints
- このフォルダ配下のみ。本体 src/ には絶対に触れない
- 試行錯誤・ハードコード・ノートブック化はすべて許容
- 結論が出たら FINDINGS.md に記録し、コードは破棄する想定
## Out of scope
- 本番API化
- データベース設計
- フロントエンド統合
使うべき機能 / 使わない機能
- ✅ Plan mode + Explore subagent:ライブラリやデータ構造の偵察
- ✅ 軽量な Slash Command(例:
/spike-logで FINDINGS.md に追記) - ❌ Hooks は基本入れない:速度を優先する。間違ったコードはコミットされない前提
- ❌ 本体の Subagent / MCP は流用しない:汚染を避ける
- ❌ docstring / 型ヒントの厳密化は不要
成果物 FINDINGS.md(ADRライト)
# Findings: Whisper LoRA on dysarthric speech (Spike #2026-05)
## Verdict
**Conditional Yes** — WER 0.32 達成、ただし以下の条件下で。
## Evidence
- Sample size: 100 utterances, 5 speakers
- Best config: LoRA rank=8, target_modules=["q_proj","v_proj"], 3 epochs
- VRAM peak: 13.8 GB / 16 GB
- Wall time: 42 min on RTX 5060 Ti
## Constraints discovered
- 音韻性錯語(phonemic paraphasia)を「修正」してしまう挙動を確認
- → 命名課題の正誤判定を Whisper 単独で行うことは **設計上禁止** とする
## Decision
Walking Skeleton 段階では Whisper 出力に対して
**別途音素レベルの比較器**を挟む構成とする(後段 Milestone で実装)。
ここで生まれた制約「Whisper alone must not judge naming tasks」は、後続の本体 CLAUDE.md の最重要セクションに昇格する。Spike の本当の出力物は動くコードではなく、こうした 設計拘束 だ。
国際標準との対応
- ADR(Michael Nygard)── FINDINGS.md が事実上の ADR
- ISO/IEC/IEEE 12207 "Risk Management Process" ── リスクの識別と低減を専用プロセスとして分離
- リーンの「学習を最大化する最小実験」
5. Stage 2: Walking Skeleton ── 端から端まで歩く骨格
目的
主要アーキテクチャコンポーネントが結線され、CIが緑で、デプロイ可能な、ほぼ空っぽのシステムを作る。 ここで実装する機能はただ一つ ── 「最も細い1本の動線」だ。例えば kotonomi なら「録音 → API → DB保存 → 結果表示」の本当に一往復だけ。
Definition of Done(Cockburnの定義に忠実に)
- 主要コンポーネント(UI / API / DB / 推論 / 認証)がすべて起動し、相互に呼び合っている
- 1本の e2e テストが通る
- Day 1 デプロイ:本番に近い環境(devcontainer + docker compose + 自社レジストリ)に load できる
- CIパイプラインが緑(lint, test, build, deploy のすべてのジョブが定義済み)
逆に DoDに含めない:
- 機能の網羅性
- パフォーマンス
- UIの美しさ
Claude Code 構成
ここから 本体の CLAUDE.md を整える。揺らがせたくない構造を Hooks で守り始める。
ディレクトリ
project-root/
├── CLAUDE.md
├── .claude/
│ ├── agents/
│ │ └── skeleton-verifier.md
│ ├── commands/
│ │ ├── skeleton-verify.md
│ │ └── walk-through.md
│ ├── specs/
│ │ └── architecture.md # C4 Container 図相当
│ └── settings.json # hooks 定義
├── src/
│ ├── api/ # FastAPI
│ ├── web/ # React/TypeScript
│ ├── infer/ # Whisper ラッパー
│ └── db/ # PostgreSQL モデル
├── tests/
│ └── e2e/
│ └── test_happy_path.py
└── docker-compose.yml
CLAUDE.md(標準版)
# kotonomi — Speech Rehabilitation App
## Project context
失語症患者の発話リハビリ支援アプリ。病院でのベッドサイド利用を想定。
## Architectural invariants (NEVER VIOLATE)
1. Whisper の出力を命名課題の正誤判定に **単独で** 使ってはならない
→ 音素比較器を経由すること
2. すべての医療データは PostgreSQL に保存し、ファイルシステムに残さない
3. API レイヤーは FastAPI、フロントは React/TypeScript で固定
## Stage indicator
**Current stage: Walking Skeleton**
DoD: docker compose up → happy_path e2e test passes.
新機能は追加しない。骨格の貫通のみ。
## Definition of Done (current stage)
- [ ] `make skeleton-verify` がローカルで緑
- [ ] GitHub Actions の build/test/deploy ジョブが定義済み
- [ ] 自社 Docker レジストリへの push が通る
## Architecture
See `.claude/specs/architecture.md` (C4 Container view).
## Coding standards
- Python: ruff + mypy strict
- TypeScript: tsc strict, biome
- すべて型を書く。`any` 禁止。
Hooks(最小構成)
.claude/settings.json に lint と test を PostToolUse / Stop に最低限だけ入れる。
{
"hooks": {
"PostToolUse": [
{
"matcher": "Edit|Write|MultiEdit",
"hooks": [
{ "type": "command", "command": "./scripts/lint-changed.sh" }
]
}
],
"Stop": [
{
"hooks": [
{ "type": "command", "command": "./scripts/skeleton-verify.sh" }
]
}
]
}
}
skeleton-verify.sh は happy-path e2e テスト1本だけ を実行する。これが「Walking Skeleton が生きている」唯一の証拠であり、ここを保護するのが Hook の役目だ。
Subagent: skeleton-verifier
---
name: skeleton-verifier
description: Verify that the walking skeleton end-to-end path still works.
Use after any structural change.
tools: Bash, Read
---
You verify that:
1. `docker compose up -d` succeeds
2. The single happy-path test `tests/e2e/test_happy_path.py` passes
3. CI workflow files are syntactically valid
You do NOT add features. You do NOT modify business logic.
If the skeleton is broken, report which layer (UI / API / infer / DB) is the cause.
設計上の禁則
Walking Skeleton 段階で起きがちな失敗は、「動くMVP」と取り違えることだ。MVPは「市場検証可能な価値を備えた最小製品」、Walking Skeleton は「アーキテクチャの結線が証明された骨格」。前者は機能要件、後者は構造要件で評価する。
Claude Code に「ついでに〇〇機能も入れて」と指示すると Walking Skeleton が崩れる。この段階の Slash Command は意図的に少なく、新機能追加系のコマンドは置かない ことが効く。
国際標準との対応
- ISO/IEC/IEEE 42010 ── 主要コンポーネントとその関係の最初の証明
- C4 Model の Container 図がそのまま
.claude/specs/architecture.mdになる - Continuous Delivery(Humble & Farley)の "Deployment pipeline first"
6. Stage 3: Milestone ── 垂直スライスの積み上げ
目的
Walking Skeleton の上に、ユーザー価値を持つ垂直スライスを一つずつ積む。各 Milestone はそれ単独で意味があり、デプロイ可能で、検証可能。
kotonomi なら例えば:
- M1: 命名課題の出題と回答記録(音素比較器を含む)
- M2: 患者ごとの履歴閲覧
- M3: セラピストによる評価入力
- M4: PDF レポート出力
各 Milestone は Spike(必要なら)→ 実装 → DoD 検証、という小さなサイクルを内包する。
Definition of Done(Milestone毎にスペックで定義)
.claude/specs/M1-naming-task.md のような Milestone スペックファイルに書く。IEEE 1016(Software Design Description)に準拠したテンプレートを社内標準とすると、複数 Milestone の DoD 品質が安定する。
# Milestone M1: Naming Task with Phonemic Verification
## User-facing goal
セラピストが命名課題を出題でき、患者の音声回答を記録・自動採点できる。
## Architectural decisions (links to ADRs)
- ADR-003: Use phoneme-level comparator after Whisper, not Whisper-only judgment
- ADR-004: Store raw audio in S3-compatible storage, transcripts in PostgreSQL
## Definition of Done
- [ ] セラピストUIから課題を出題できる
- [ ] 患者が録音し、音声がアップロードされる
- [ ] Whisper → 音素比較器 → 採点結果がDBに保存される
- [ ] e2e テスト追加(M0の skeleton path とは別ファイル)
- [ ] 単体テストカバレッジ 70% 以上
- [ ] CHANGELOG.md に追記
- [ ] 自社レジストリにタグ `v0.1.0-m1` で push 成功
## Out of scope
- 複数患者の同時セッション(M5)
- レポート出力(M4)
Claude Code 構成
ここでようやく マルチエージェント運用 に入る。各役割を最小権限で分離する。
サブエージェント編成(役割分離)
.claude/agents/
├── planner.md # 設計フェーズ専用。実装ツールなし
├── implementer.md # コード書き込み可
├── reviewer.md # 読み取り専用、レビュー出力
├── tester.md # テスト実行とテスト追加のみ
└── skeleton-verifier.md # Walking Skeleton 段階から引き継ぎ
例えば planner.md:
---
name: planner
description: Decompose a milestone spec into implementation tasks.
Use BEFORE any code is written.
tools: Read, Grep, Glob
---
You take a milestone spec from .claude/specs/ and produce a task plan.
You produce no code. You produce a numbered list of edits with
- file paths to touch
- expected diff size
- testing strategy per task
You stop after producing the plan. Implementation is the implementer's job.
reviewer.md:
---
name: reviewer
description: Review changes against CLAUDE.md invariants and the active milestone spec.
Use after implementation, before commit.
tools: Read, Grep, Glob, Bash
---
Check each diff against:
1. CLAUDE.md "Architectural invariants" — flag any violation
2. The active spec in .claude/specs/ — flag any DoD item not covered
3. Coding standards — flag type holes, `any`, missing tests
Output a structured report. Do not modify files.
権限分離(tools フィールド)が least-privilege の原則を構造で実現していることに注目してほしい。これは Hooks の PreToolUse で検証することもできるが、エージェント単位で絞るほうがシンプルで監査もしやすい。
Hooks(本格運用)
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{ "type": "command", "command": "./scripts/guard-dangerous.sh" }
]
}
],
"PostToolUse": [
{
"matcher": "Edit|Write|MultiEdit",
"hooks": [
{ "type": "command", "command": "./scripts/lint-changed.sh" },
{ "type": "command", "command": "./scripts/type-check.sh" }
]
}
],
"Stop": [
{
"hooks": [
{ "type": "command", "command": "./scripts/check-dod.sh" }
]
}
],
"SessionStart": [
{
"hooks": [
{ "type": "command", "command": "./scripts/load-active-spec.sh" }
]
}
]
}
}
ポイントは、Hooks は CLAUDE.md に書かれた規約を機械的に強制する補助線だということ。
たとえば check-dod.sh は、.claude/specs/ 配下の active spec を読んで、未チェックの DoD 項目があれば exit code 2 を返す。Claude Code はセッションを終わらせられない。これがリーン生産方式における poka-yoke(ポカヨケ・誤防止) の精神そのものだ。
MCP サーバ
Milestone 段階では外部統合の本数が増える。kotonomi の例:
- PostgreSQL MCP:DB スキーマの照会、サンプルクエリ
- GitHub MCP:Issue / PR 連動
- Filesystem MCP:制御された範囲のファイル参照
ただし、MCP は 読み取り権限から始める。書き込み可能なMCPは個別の Subagent にのみ渡し、メインセッションには付与しない。これも least-privilege。
Slash Commands
.claude/commands/
├── m-start.md # /m-start M1 → spec読み込み・planner起動
├── m-review.md # /m-review → reviewer起動
├── m-ship.md # /m-ship → DoD最終確認・タグ・push
└── spike.md # /spike <topic> → spikes/配下に新規Spike環境を作る
m-start.md の例:
---
name: m-start
description: Start work on a milestone. Loads the spec and invokes the planner.
---
1. Read `.claude/specs/$ARGUMENTS.md`
2. Confirm all referenced ADRs exist in `docs/adr/`
3. Invoke the `planner` subagent with the spec content
4. Present the plan to me for approval before any implementation
Milestone を「期日」と取り違えないために
PMBOK の定義は明確に "a significant point or event in the project" であり、日付ではない。Claude Code 運用上も、Milestone は
- 「○月×日まで」ではなく
- 「DoD のチェック項目が全部通って、
m-shipが成功した瞬間」
として扱う。Hook の check-dod.sh が事実上の milestone gate になる。
国際標準との対応
- PMBOK / ISO/IEC/IEEE 12207 ── Stage Review の自動化
- IEEE 1016 ── スペックファイルの形式
- Scrum DoD ── milestone spec の DoD セクション
- Lean / TPS の jidoka(自働化)── Hooks による品質ビルトイン
7. ステージ間遷移の判断基準
3段階運用で最も難しいのは 段階を進める判断だ。早すぎても遅すぎても破綻する。
Spike → Walking Skeleton
進める条件:
- リスク質問に対する Verdict(Yes / No / Conditional Yes)が出ている
- 主要技術コンポーネントの選定が確定している
- アーキテクチャ拘束が CLAUDE.md ドラフトに書き出せている
戻る条件:
- Walking Skeleton 構築中に「この設計で本当に動くか」の疑問が再浮上 → 別の Spike を切る
Walking Skeleton → Milestone
進める条件:
- e2e ハッピーパスが通り、CI緑、デプロイ可能
- 本番に近い環境で骨格が起動している
- すべての主要コンポーネントが結線済み
戻る条件:
- Milestone 実装中に「コンポーネント間の結線」レベルでつまづく → Walking Skeleton に手を入れる
Milestone → 次の Milestone
進める条件:
- 現 Milestone の DoD がすべてチェック済み
m-ship成功- 振り返り(ADR追記の必要性確認)完了
8. 落とし穴
8.1 Spike をリポジトリ本流に混ぜる
最頻出。Spike の本質は「捨ててよい」ことなので、本流に混ざった瞬間に捨てられなくなり、技術的負債になる。spikes/ という物理隔離と、別 CLAUDE.md による文脈分離で防ぐ。
8.2 Walking Skeleton を MVP と混同する
MVP は機能要件、Walking Skeleton は構造要件。混同すると「最小機能を作るつもり」で UI や業務ロジックを膨らませてしまい、骨格が「肉付きの貧弱な MVP」になる。ステージインジケータを CLAUDE.md に明示することで防ぐ。
8.3 Milestone を期日と扱う
「次の Milestone は来週金曜まで」と書いた瞬間に、Milestone は DoD ではなくカレンダーで切られるようになり、検証可能性が消える。期日はマイルストーンの属性ではなくスケジュールの属性として別文書に置く。
8.4 Hooks に CLAUDE.md と同じことを書く
両者は補完関係であって冗長関係ではない。CLAUDE.md は「なぜそうするか」を含めた規範、Hooks は「それを破ったら止める」反射神経。同じ内容を書くと、Hooks の決定論的性質が薄まる。
8.5 全段階で同じサブエージェント編成を使う
Spike では implementer 一人で十分(むしろ planner を挟むとオーバーヘッド)。Milestone では分離が効く。段階ごとに .claude/agents/ のサブセットを使う意識が必要だ。
9. まとめ:AI時代の設計手法は「更新」ではなく「強化」
Spike / Walking Skeleton / Milestone は、いずれも AI 以前から存在する設計概念だ。Claude Code の登場で、これらが古びたわけでも置き換わったわけでもない。むしろ逆で、生成速度が上がったぶん、構造的足場の重要性が増している。
BitOn での 3 段階運用が示しているのは、
- 古典的設計手法は「Claude Code の構成要素」に1対1で写像できる
- 写像のさせ方には設計者の意図が現れる(どこを CLAUDE.md で、どこを Hooks で、どこを Subagent 分離で守るか)
- 写像を文書化することで、チームが Claude Code を使う流儀そのものが資産になる
ということだ。
AI支援開発は「コーディングの自動化」ではない。「設計プロセスの再記述」だと捉えるとき、Spike・Walking Skeleton・Milestone は、これからも先頭で機能し続ける。
参考文献
- Beck, K. Extreme Programming Explained, 2nd ed., 2004.
- Cockburn, A. Agile Software Development: The Cooperative Game, 2nd ed., 2006.
- Cockburn, A. Crystal Clear, 2004.
- Humble, J., Farley, D. Continuous Delivery, 2010.
- Nygard, M. Documenting Architecture Decisions, 2011.
- Brown, S. The C4 Model for Software Architecture. https://c4model.com/
- PMI. PMBOK Guide, 7th ed.
- ISO/IEC/IEEE 12207:2017 — Software life cycle processes.
- ISO/IEC/IEEE 42010:2022 — Architecture description.
- IEEE 1016-2009 — Software Design Descriptions.
- Anthropic. Claude Code Documentation. https://docs.claude.com/en/docs/claude-code/overview